 Modern platforms reduce delivery friction and improve trust in data products.
Modern platforms reduce delivery friction and improve trust in data products.
Modern data stacks were supposed to make things easier: faster insights, self-serve analytics, dependable pipelines. Instead, many organizations ended up with something else entirely—more tools, more integration work, more handoffs, more cloud spend, and a growing gap between “data work” and real business outcomes.
And now we’re layering AI copilots and autonomous agents on top.
That’s not inherently bad. But it’s risky if we treat AI like a shortcut around fundamentals. AI doesn’t replace data discipline—it amplifies whatever you already have. If your data is reliable and governed, AI can accelerate delivery. If your data is messy and poorly owned, AI will accelerate confusion.
In 2026, AI isn’t a replacement for data modernization. It’s the reason you can’t afford to skip it.
This post lays out a modernization approach we use at The Data Consulting Company—one that prioritizes simplicity, ownership, and reliability so your data platform becomes an asset (not a second job).
The real problem: modernization became “complex by default”
Most teams didn’t choose complexity because they love complexity. They chose it one decision at a time:
- “We need a tool for ingestion.”
- “We need a tool for orchestration.”
- “We need a tool for quality.”
- “We need a tool for cataloging.”
- “We need a tool for streaming.”
- “We need a tool for transformation.” -“ We need a tool for governance.”
Eventually, “modern” becomes a tangle of overlapping capabilities and unclear responsibility. When something breaks, teams argue about whether it’s the source system, the ingestion service, the transformation code, the warehouse, permissions, the BI layer, or a semantic model.
And with AI, there’s a new contender: the model and its retrieval layer.
The future isn’t more tools. It’s fewer problems.
A 2026 reality check: AI agents don’t fix the foundation
AI agents can write SQL, generate dbt models, propose pipelines, and even trigger operational tools. That sounds magical—until you remember what agents actually do: they act on your systems.
That means your data platform needs to be:
- understandable (clear boundaries and ownership),
- trustworthy (quality and lineage),
- governed (access controls, privacy, compliance),
- observable (you can detect and respond to failures),
- testable (changes don’t silently degrade outputs).
Without those, “agentic automation” isn’t modernization—it’s automation of instability.
Don’t agent your mess. Fix the mess, then automate.
Framework: Modernize by simplifying
Here’s the model we use to guide modernization work. It’s intentionally unsexy. That’s the point.
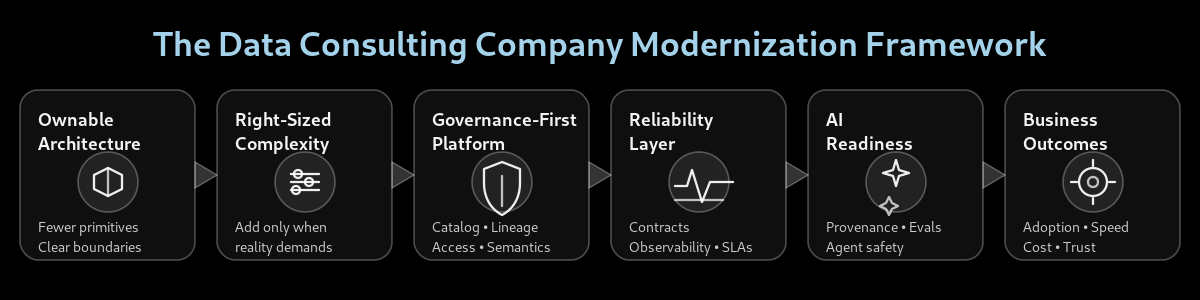
Ownable Architecture → Right-Sized Complexity → Governance-First → Reliability Layer → AI Readiness → Outcomes
1) Ownable architecture beats “best-of-breed sprawl”
Modernization should reduce integration tax, not increase it. If your platform requires a dozen vendors and three specialists to debug a broken dashboard, you don’t have a platform—you have a dependency graph.
Best practice in 2026 is choosing a small set of durable primitives:
- storage + compute,
- orchestration,
- catalog/lineage,
- observability,
- access controls,
- a standard transformation pattern.
Everything else should earn its place.
If your architecture can’t be explained on one whiteboard, it’s already a risk.
2) Add complexity only when reality demands it
Many organizations build for “future scale” that never arrives, then spend years paying for the complexity.
Instead:
- start with a thin vertical slice (one domain → one governed dataset → one outcome),
- prove adoption and reliability,
- scale patterns, not bespoke pipelines.
Streaming, CDC, multi-region, feature stores, vector search—these are great tools when required. They’re expensive distractions when they’re not.
Build for the next 12 months, not the next 12 hypotheticals.
3) Right-sized compute: local-first + embedded analytics where it fits
Not every workload needs a distributed cluster and a sprawling toolchain. A large share of business analytics is “medium data, high expectations.” In those cases, local-first engines and embedded analytics can eliminate layers of overhead.
The best-practice mindset is pragmatic:
- use local-first approaches for exploration, prototyping, and certain production workloads where reliability and cost are superior,
- embed analytics closer to product experiences when that drives adoption,
- reserve heavy distributed architecture for workloads that truly need concurrency, SLAs, and scale.
The best stack is the one your team doesn’t have to think about every day.
4) Governance-first: the prerequisite for trustworthy AI
Governance isn’t a “phase 2” anymore. In 2026, governance is the enabling layer for:
- compliance and privacy,
- secure self-serve analytics,
- consistent metrics,
- and trustworthy AI outputs.
Governance-first means:
- a catalog that people actually use,
- lineage that’s accurate enough to debug,
- access controls that match real roles,
- shared definitions for metrics and entities.
If you can’t answer “where did this number come from?” you’re not AI-ready.
AI doesn’t make governance optional. It makes it non-negotiable.
5) Reliability by design: contracts + observability
This is where modern stacks win—when implemented correctly.
Two capabilities are becoming foundational:
Data contracts
Treat datasets as products with expectations:
- schemas,
- semantics,
- SLAs (freshness/availability),
- validation rules,
- and clear owners.
Contracts reduce breakage and prevent “silent failure” downstream.
Data observability
Observability turns unknown failure into managed risk:
- lineage-aware monitoring,
- freshness/volume/anomaly detection,
- incident workflows,
- and measurable reliability.
When contracts and observability work together, your platform becomes safer to change—which is the real secret to moving faster.
Speed comes from safety. Safety comes from reliability engineering.
6) AI readiness: RAG discipline + agent safety + evaluation
AI readiness is not “we connected a model to our warehouse.”
It’s a set of disciplines:
RAG readiness
- controlled source selection,
- PII handling and redaction rules,
- chunking standards,
- provenance (citations/traceability),
- and retrieval evaluation (relevance, coverage, regression tests).
Agent safety If agents can take actions, your security model must assume:
- prompt injection attempts,
- data exfiltration attempts,
- and tool misuse.
Best practices:
- strict allowlists for tools,
- least-privilege permissions,
- sandboxed execution,
- audit logs,
- and a “human-in-the-loop” policy where it matters.
Evaluation harnesses
If you can’t measure output quality, you can’t operate AI in production. Evals aren’t optional—they’re the new unit tests.
If you can’t test it, you can’t trust it. If you can’t trust it, don’t automate it.
What modernization success actually looks like
A modern platform isn’t defined by tool brands. It’s defined by outcomes:
- Adoption: business teams use governed data without filing tickets
- Speed: new datasets and features ship faster with fewer incidents
- Trust: people believe dashboards and AI answers because provenance exists
- Cost control: cloud spend is intentional and visible
- Resilience: failures are detected early, triaged quickly, and prevented systematically
How The Data Consulting Company helps
We help organizations modernize by simplifying:
- Architecture you can own: fewer moving parts, clear responsibilities
- Governance-first execution: catalog, lineage, access, semantics—implemented as a working system
- Reliability engineering: contracts, observability, incident playbooks, and operational SLAs
- AI readiness done right: RAG evaluation, provenance, and agent safety controls
- Outcome-driven delivery: modernization measured by adoption, trust, and velocity—not tool count
Final thought
Modernization isn’t about stacking new technologies. It’s about removing friction—so your data platform becomes invisible, dependable, and scalable when you actually need it.
The best data stack is the one you never have to think about.